Hexo添加Google收录与SEO
刚给网站做了SEO,顺道来更新一篇4年前的老博文。本文内容包括:安装插件并生成网站地图,通过配置插件来剔除不需要收录的页面或文件,向谷歌搜索提交网站地图并添加收录,以及使用robots.txt来进行搜索引擎优化(SEO)
插件安装与配置
安装
首先,我们需要安装hexo-generator-sitemap插件来为网站生成网站地图(Sitemap),命令如下:
1 | npm install hexo-generator-sitemap --save |
配置
安装完成后打开Hexo框架的配置文件./_config.yml,向其中添加下面的配置:
1 | # Sitemap Generator |
说明:
path是生成的网站地图的路径,例如我的网站URL是https://siriusq.top/,那么生成的网站地图的路径就是https://siriusq.top/sitemap.xmltags用于设置是否收录标签相关页面,我关闭了这个选项,因为我的标签数量比博文还多🐶,而每个条标签都会生成一条索引,喧宾夺主categories用于设置是否收录分类相关页面,按需开启- 更多选项可以到插件README页面查看
排除特定页面
如果你不想让特定的页面(例如404页面)出现在网站地图中,可以在相关页面的MarkDown文件最上方以---分隔的区域(Front-matter)中添加一行sitemap: false,示例如下:
1 |
|
排除特定格式文件
插件默认会排除js和css格式的文件,但是我的网站有很多json格式的Live2D模型配置文件,它们在页面生成过程中都会被添加到网站地图中,数量达到了恐怖的93条,我的博文索引还不到60条🐶。
但是插件并没有提供排除特定格式文件的配置选项,谷歌查到的在./_config.yml的插件配置中添加exclude: '/**/*.json'语句也是无效的,不知道这个设置是怎么传出来的,我看了一下插件源码,根本就没有这个选项。
解决方案非常的简单粗暴,直接改插件代码🐶。打开博客目录下的./node_modules/hexo-generator-sitemap/lib/generator.js,找到const skipRenderList,像其中添加一行'**/*.json',改完之后是下面这个样子,注意不要漏掉上一行结尾处的逗号。
1 | const skipRenderList = [ |
添加到谷歌收录
目前网站还不能够通过搜索引擎搜索到,想要被搜到的话需要添加搜索引擎收录,这里以我添加的Google为例。
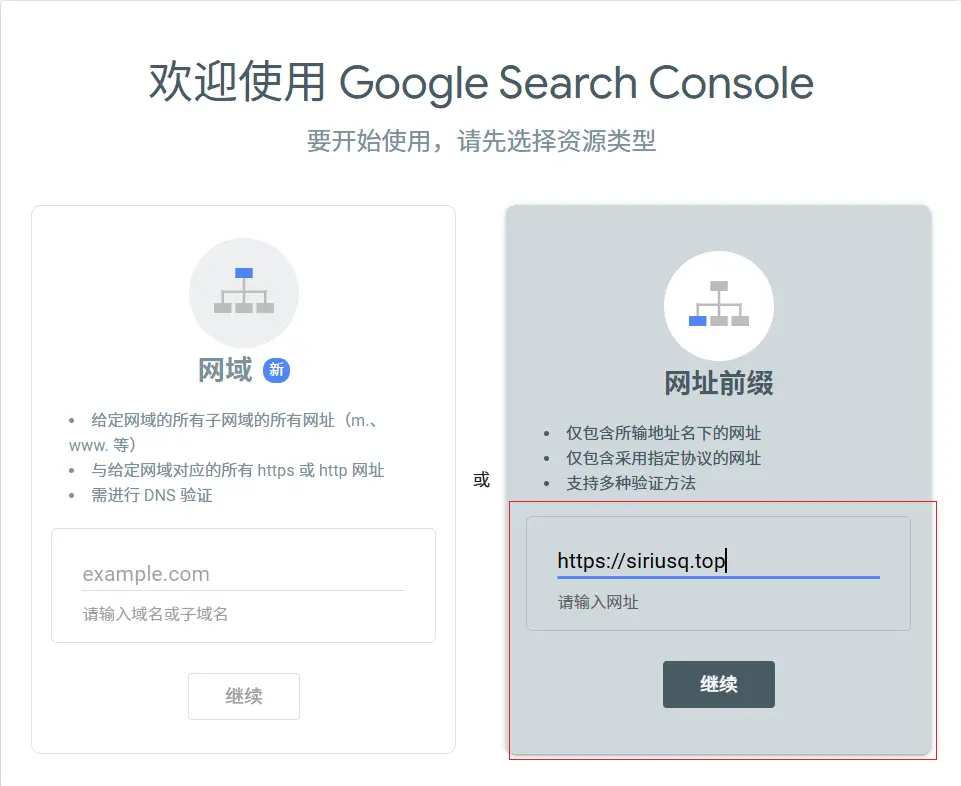
- 打开Google Search Console,点击立即使用并登录谷歌账号
- 选择网址前缀并输入站点网址,如
https://siriusq.top,点击继续![01.webp]()
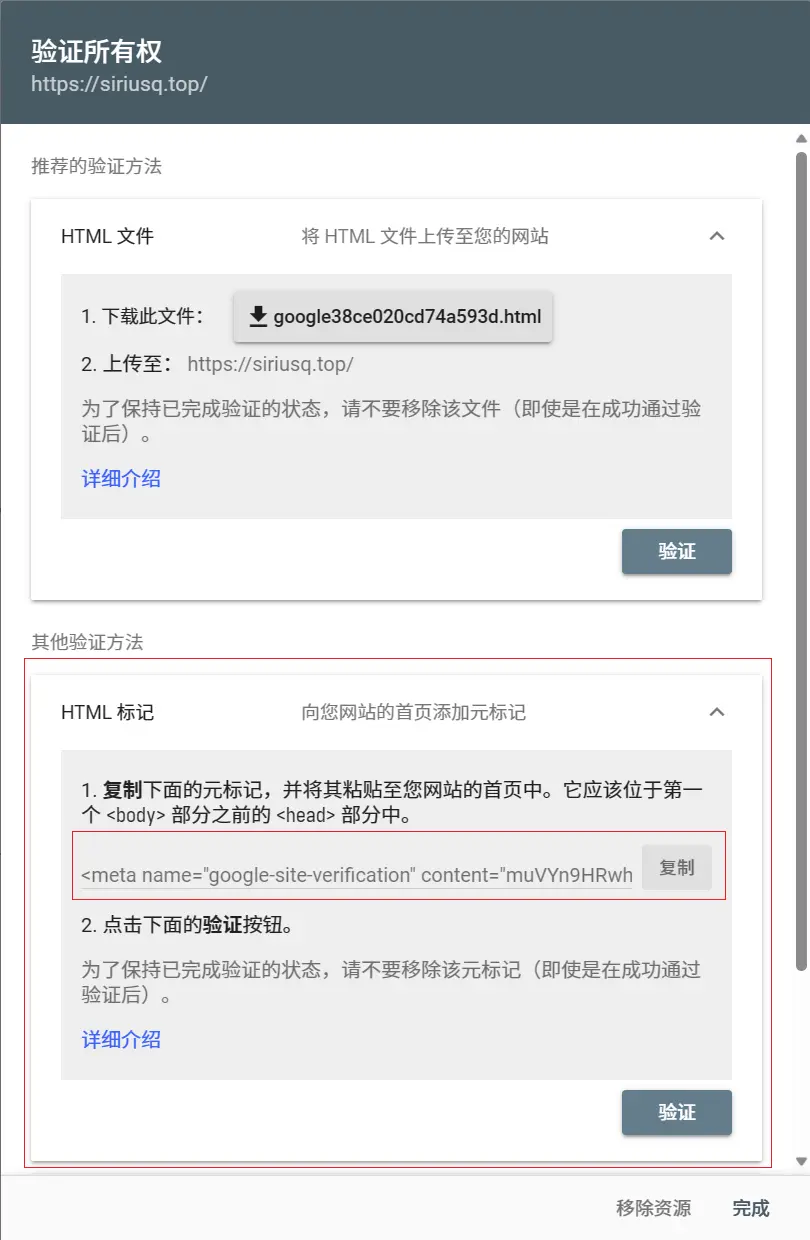
- 验证方法选择HTML标记,然后复制Google提供的元标记,如:
1 | <meta name="google-site-verification" content="tcRYfdvRwh-85F9TY63_0TZ4O56GfhgyNGZhgfzsdfgghfg" /> |
4. 打开Next主题配置文件_config.next.yml,通过搜索找到google_site_verification:,在后面粘贴上一步复制的元标记中的content部分,如:
1 | google_site_verification: tcRYfdvRwh-85F9TY63_0TZ4O56GfhgyNGZhgfzsdfgghfg |
5. 执行
hexo cl与hexo g -d命令,重新生成网站资源并推送到GitHub,在博客仓库的Actions中查看网站是否完成部署6. 完成部署后回到第3步的网页,点击
验证即可7. 过一段时间(最长可能要1个月),等待Google的爬虫完成对网站的索引,然后在Google中搜索
site:域名就可以看到自己的网站了8. 建议在验证完成后手动提交一份网站地图
- 点击Google Search Console左边栏中
站点地图 - 网站地图的默认URL是
https://[你的博客域名]/sitemap.xml - 粘贴URL并点击
提交即可
设置robots.txt
robots.txt 是一个文本文件,用于控制搜索引擎爬虫访问网站的权限。我们可以在网站的根目录中放置这个文件,以指定哪些页面或目录可以被搜索引擎的爬虫访问,哪些不可以。
以下是 robots.txt 的一些常用元素和规则:
User-agent:指定要应用规则的搜索引擎爬虫的名称。例如,”User-agent: Googlebot” 表示以下规则适用于 Googlebot 爬虫。常见爬虫名称如下Googlebot- Google 的搜索引擎爬虫。Bingbot- Microsoft Bing 的搜索引擎爬虫。Slurp- 雅虎的搜索引擎爬虫。DuckDuckBot- DuckDuckGo 的搜索引擎爬虫。Baiduspider- 百度的搜索引擎爬虫。YandexBot- Yandex 的搜索引擎爬虫。
Disallow:指定不允许爬虫访问的页面或目录。例如,”Disallow: /private/“ 表示不允许爬虫访问网站中的 “/private/“ 目录。Allow:用于取消Disallow规则的限制。如果一个目录被Disallow,但其中的某些文件或子目录需要被爬取,可以使用Allow来解除限制。Crawl-delay:指定爬虫爬取网站的速度。这个规则通常用于控制爬虫的爬取速度,以避免对服务器造成过大的负载。Sitemap:告诉搜索引擎关于网站地图(Sitemap)的位置,这通常用于帮助搜索引擎更好地理解网站结构。
robots.txt示例
一个简单的 robots.txt 文件的示例:
1 | User-agent: Googlebot |
在这个示例中,对 Googlebot 的规则是不允许访问 “/private/“ 目录,但允许访问 “/public/“ 目录,而且限制它的爬取速度。对于 Bingbot,不允许访问 “/admin/“ 目录。
来自 ChatGPT
下面是我的robots.txt,它禁止百度爬虫爬取网站(垃圾百度你不配),然后阻止其他爬虫爬取无关的目录与404页面。
1 | User-agent: Baiduspider |
关于robots.txt的更多信息请参阅Google搜索中心